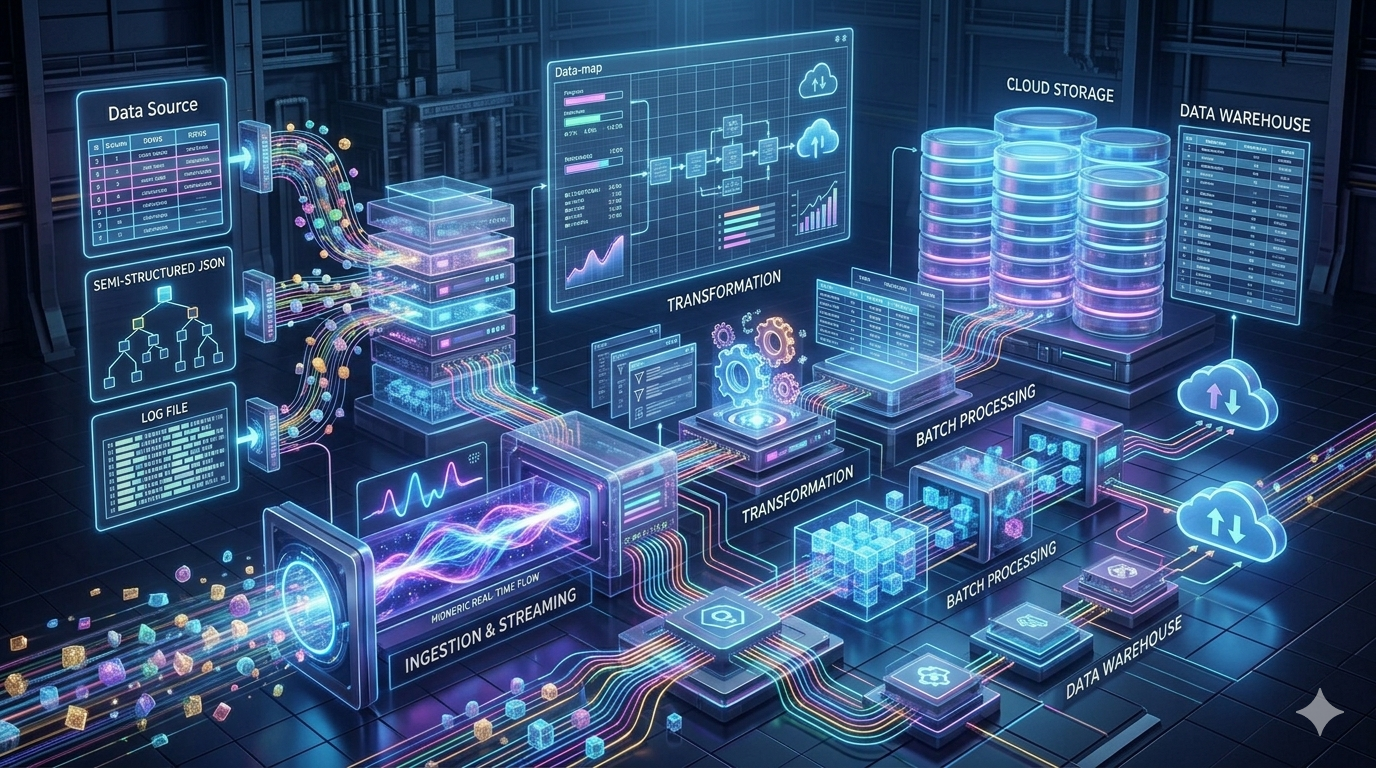
In today’s data-driven business environment, Customer Relationship Management (CRM) systems have become the backbone of operational efficiency. Companies rely on CRM platforms to store customer profiles, track interactions, and manage sales pipelines. As organizations grow, the volume and complexity of CRM data increase significantly. Without proper strategies, integrating and processing this data can become slow, error-prone, and costly. This is where scalable ETL (Extract, Transform, Load) pipelines come into play. Designing an ETL pipeline that efficiently handles CRM data ensures timely insights and smooth operations, while maintaining accuracy and consistency across multiple sources.
Understanding CRM Data
CRM data is diverse and originates from multiple touchpoints. Typical data types include customer demographics, purchase history, communication logs, and marketing engagement metrics. The sources may range from SaaS platforms like Salesforce, HubSpot, and Microsoft Dynamics 365 to custom-built databases. Often, data comes in structured formats, such as relational tables, or semi-structured formats, like JSON and XML, with occasional unstructured content, including email communications or chat transcripts. Integrating these sources requires careful handling of discrepancies in data formats, duplicates, and missing information. Ensuring high-quality data is essential because poor-quality input can compromise business intelligence and reporting accuracy. For instance, using Salesforce Sales Cloud IVR API Integration allows organizations to synchronize voice interaction data with their CRM seamlessly. By embedding this integration within ETL pipelines, businesses can enrich customer profiles with call logs and IVR interactions, providing a unified view of customer engagement.
Key Principles of Scalable ETL Design
A robust ETL design should prioritize scalability and maintainability. Modularity is fundamental; each ETL stage—extraction, transformation, and loading—should be implemented as a discrete, reusable component. This approach simplifies testing and enables easy upgrades without disrupting the entire pipeline. Parallelization further enhances performance by processing multiple tasks concurrently, reducing overall runtime for large datasets. Implementing incremental loads, rather than full refreshes, ensures that only new or updated records are processed, minimizing computational overhead. Additionally, incorporating data validation and monitoring is critical to maintain data integrity and catch errors early. Finally, pipelines must be equipped with robust error handling and retry mechanisms, preventing minor failures from cascading into major operational issues.
Architecture Patterns for ETL Pipelines
Choosing the right architecture is crucial for handling growing CRM data volumes efficiently. Batch processing works well for scheduled, high-volume data loads, while real-time streaming supports continuous ingestion from dynamic sources. Advanced designs such as Lambda and Kappa architectures enable hybrid pipelines, allowing both batch and real-time processing for optimal performance. Cloud-based ETL services, including AWS Glue, Azure Data Factory, and Google Cloud Dataflow, provide built-in scalability and flexibility, reducing infrastructure management overhead. For data storage, organizations often integrate ETL pipelines with data lakes for raw data collection and data warehouses for structured reporting and analytics. Selecting the right combination ensures that pipelines can scale efficiently without compromising reliability.
Data Transformation Best Practices
Transforming CRM data requires both standardization and enrichment. Field normalization ensures consistent formats across sources, such as unifying date formats or standardizing phone numbers. Deduplication removes repeated customer entries, preventing skewed analytics. Enrichment involves integrating external sources, including social media, transactional databases, and marketing platforms, to provide a comprehensive view of each customer. Maintaining historical data is equally important; Slowly Changing Dimensions (SCDs) enable tracking changes in customer attributes over time. When combined with APIs like Salesforce Sales Cloud IVR API Integration, transformation processes can incorporate voice and interaction metadata, adding depth to customer insights. Properly structured transformations facilitate downstream analytics, predictive modeling, and business intelligence reporting.
Optimizing ETL Performance
High-volume CRM data necessitates careful performance optimization. Partitioning large datasets and indexing key columns accelerates query performance. Utilizing caching mechanisms can reduce redundant computations and speed up data processing. Choosing the right storage formats, such as Parquet, ORC, or Delta Lake, improves read/write efficiency while minimizing storage costs. Load balancing ensures that pipeline resources are distributed effectively across multiple nodes, preventing bottlenecks. Additionally, concurrency control avoids conflicts when multiple processes attempt to modify the same dataset simultaneously. Together, these strategies create ETL pipelines that can scale horizontally to meet increasing business demands.
Monitoring and Observability
Observability is essential for maintaining reliable pipelines. Detailed logging of each ETL stage allows teams to trace errors and identify performance bottlenecks quickly. Metrics such as pipeline latency, throughput, and error rates provide insights into operational health. Automated alerts notify engineers of failures or anomalies, enabling swift corrective action. Data lineage tracking ensures transparency by recording the origin and transformation of every data point. For organizations dealing with sensitive CRM data, this visibility supports both operational efficiency and regulatory compliance.
Security and Compliance
CRM pipelines must safeguard customer data against breaches and unauthorized access. Encrypting data in transit and at rest is standard practice, while implementing role-based access control (RBAC) restricts sensitive operations to authorized personnel. Compliance frameworks like GDPR and HIPAA impose strict rules on storing, processing, and sharing customer information. Designing ETL pipelines with these considerations ensures data security, protects customer privacy, and mitigates legal risks.
Case Study: Implementing a Scalable CRM ETL Pipeline
Consider a mid-size enterprise integrating Salesforce CRM with additional customer interaction systems. The organization implemented an ETL pipeline that extracted customer and interaction data daily. Using modular transformations, they standardized all fields, deduplicated records, and enriched profiles with email and IVR data. Incremental loads were employed to process only new interactions, significantly reducing compute time. Data was loaded into a cloud data warehouse, partitioned for performance, and monitored with automated alerts. As a result, reporting latency dropped by 60%, errors were minimized, and the analytics team gained a complete, up-to-date view of customer behavior.
Conclusion
Designing scalable ETL pipelines for CRM data requires careful planning, robust architecture, and continuous optimization. By following best practices in modularity, parallelization, and incremental processing, organizations can handle increasing data volumes efficiently. Integration of APIs like Salesforce Sales Cloud IVR API Integration enriches pipelines with valuable interaction data, enhancing customer insights. Optimized performance, coupled with monitoring, security, and compliance measures, ensures reliable and maintainable data workflows. As businesses increasingly rely on data-driven decision-making, scalable ETL pipelines become essential for unlocking the full potential of CRM systems


